Vision Models Adversial Attacks
Cet article couvre les attaques de type FGSM et PGD
- published
- reading time
- 11 minutes
AUTEUR : Youness LAGNAOUI x CGI BUSINESS CONSULTING
I. INTRODUCTION
Avant de voir comment attaquer un modèle de vision il faut revenir sur ce qu’est un modèle de vision, à quoi ça sert et comment ça fonctionne.
1. Qu’est-ce qu’un modèle de vision ?
Un modèle de vision est un type de modèle d’intelligence artificielle permettant à un ordinateur de comprendre et interpréter des images ou des vidéos.
Un modèle de vision permet notamment :
- la reconnaissance d’objet
- la segmentation d’image
Les modèles de vision sont couramment utilisés dans les domaines :
- Reconnaissance faciale
- Conduite autonome
- Analyse médicale
Les modèles de vision font partie d’un concept plus large : la “Vision par ordinateur” (Computer Vision). Les modèles de vision contribuent à simuler l’un des cinq sens humains : la vue.
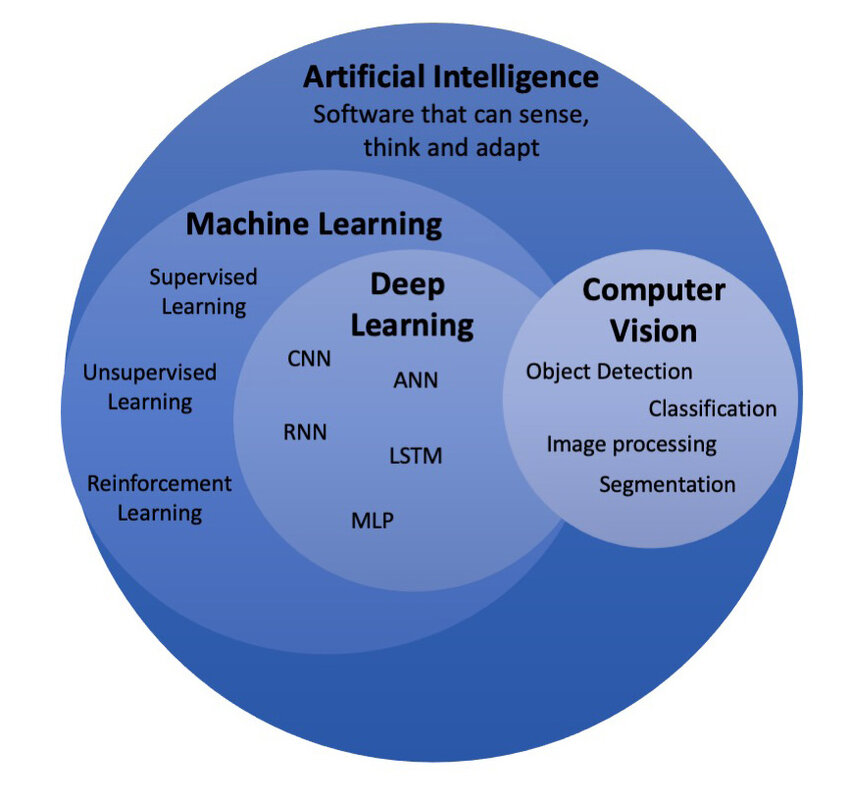 source : https://www.researchgate.net/figure/Artificial-intelligence-and-its-subfields_fig1_379731735
source : https://www.researchgate.net/figure/Artificial-intelligence-and-its-subfields_fig1_379731735
2. Fonctionnement d’un modèle de vision :
a. Conception et développement :
Comme tout type de modèle d’intelligence artificielle, la première phase de développement d’un modèle de vision est le choix ainsi que la collecte des données qui serviront au modèle pour s’entrainer à être capable de reconnaitre des éléments (labels) au sein de données visuelles comme des images ou des vidéos.
La seconde étape consiste à choisir le type d’algorithme le plus adapté pour entrainer le modèle. Voici quelques exemples d’algorithme couramment utilisés pour le développement de modèles de vision :
- K-means clustering : segmentation de couleurs
- U-Net : segmentation de structure
- Mask R-CNN : segmentation objet par objet
- CNNs (Réseaux de neurones de convolution) : classification d’images
Ces différents algorithmes/réseaux de neurones prennent en entrée de la donnée sous forme :
- modèles basés sur le framework PyTorch :
(N, C, H, W)
- modèles basés sur le framework Tensorflow/Keras:
(N, H, W, C)
Avec :
- N = nombre d’images (batch size)
- C = nombre de canaux (3 pour des images RGB, 1 pour des images en nuance de gris)
- H = hauteur des images
- W = largeur des images
Pour la suite du développement de cet article, prenons l’exemple du développement d’un modèle de reconnaissance d’espèces de chiens :
- Première étape:
- Choix des espèces de chien que l’on veut que le modèle reconnaisse. Les différentes espèces constituent les différents labels.
- Fabrication d’un dataset d’images des chiens correspondant aux différentes espèces (labels) à reconnaitre. Dans le cas d’un modèle de computer vision la majorité des modèles se basent sur de l’entraînement supervisé. Ainsi le dataset doit être de la forme
IMAGE --> label
- Deuxième étape :
- Choix de l’algorithme le plus adapté dans le cas de la reconnaissance de chien. Dans notre cas, pour de la reconnaissance d’espèces de chien, un modèle de type CNN (Réseau de neurones de convolution) permettant de faire de la classification d’image serait pertinent.
b. Entraînement du modèle
Une fois avoir construit le dataset servant à l’entraînement du modèle et choisi le type d’algorithme/réseau de neurones adapté à l’objectif du modèle, la troisième étape consiste à entrainer le modèle.
Durant cette phase le modèle apprend, à partir des données d’entrainement, à reconnaitre des paternes.
Dans le cas de l’entraînement d’un réseau de neurones de convolution, la phase d’entraînement sert à optimiser les différents poids (appelés poids synaptiques) pour classifier avec précision les images qu’il reçoit en entrée du modèle
c. Evaluation du modèle
Une fois le modèle entraîné, on peut mesurer ses performances. Pour ce faire on peut utiliser 4 différents types de mesure :
- Accuracy : (nombre total de bonnes prédictions) / (nombre total de prédictions)
- Precision : (nombre de vrais positifs) / (nombre de vrais positifs + faux positifs)
- Recall : (nombre de vrais positifs) / (nombre de vrais positifs + nombre faux négatif)
- F1-Score : 2 * (precision * recall) / (precision + recall)
Dans le cas d’un modèle permettant de faire de la classification d’image sur plusieurs labels, il est possible de tracer une matrice de confusion permettant d’observer les performances par label traité par le modèle.
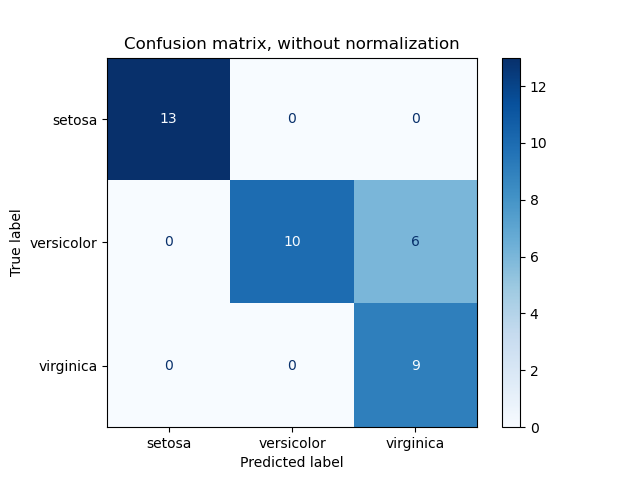
Chaque label dispose également d’une fonction de perte. Une fonction de perte correspond aux écarts entre les mauvaises et les bonnes prédictions réalisées par le modèle. Ainsi, pour qu’un modèle soit performant, il faut réduire au maximum cette fonction de perte. (gardons bien ça à l’esprit pour comprendre le mécanisme des attaques adversiales)
Jusqu’à présent nous avons vu des éléments théoriques de conception, de développement et d’évaluation de modèle de vision.
Maintenant, regardons comment attaquer ce genre de modèles.
II. Attaques Adversiales
Une attaque adversariale est une méthode utilisée pour tromper un modèle d’apprentissage automatique en modifiant de manière subtile, mais ciblée les données d’entrée (comme des images, des textes, etc.) de façon à induire une erreur de prédiction. Ces modifications sont généralement invisibles ou imperceptibles pour l’humain, mais perturbent suffisamment le modèle pour qu’il fasse des erreurs de classification ou de prédiction.
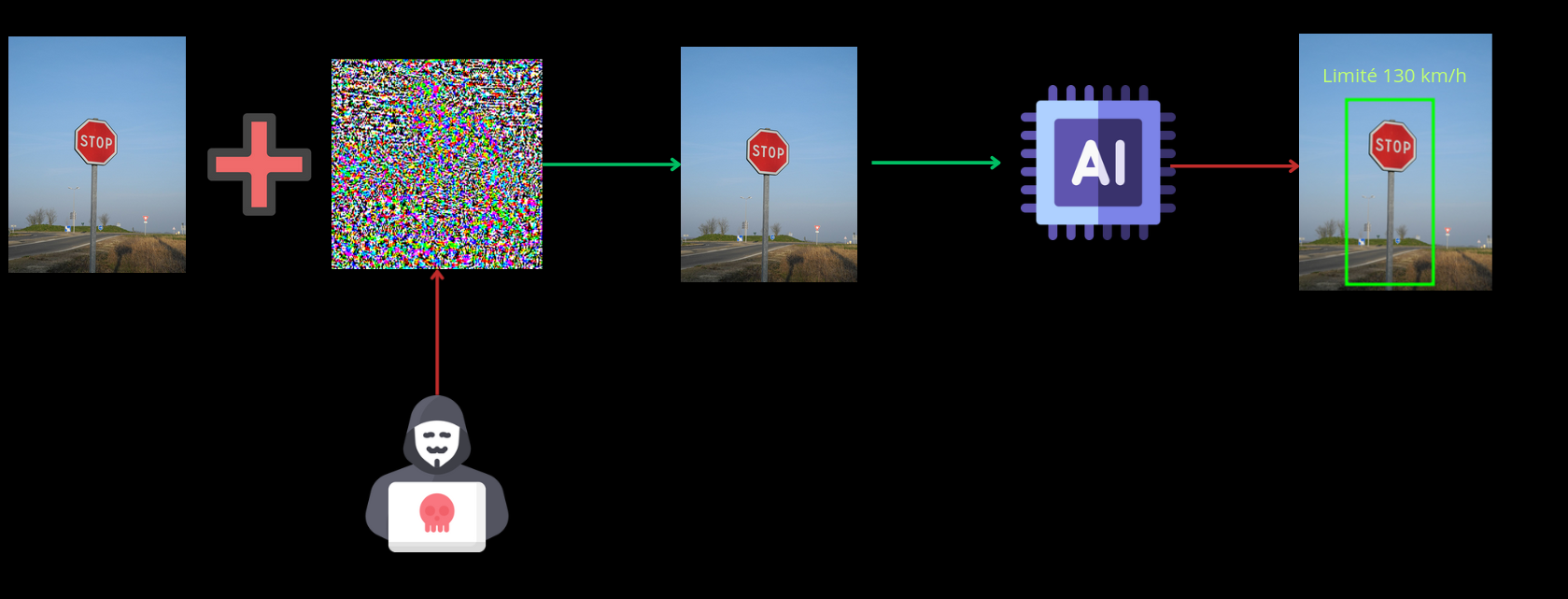
Ce genre d’attaque peut avoir de graves conséquences en termes de sécurité. En effet, on peut prendre le cas de l’application de modèles de vision pour la conduite autonome de véhicules : si un attaquant parvient à effectuer une attaque adversiale visant à tromper le modèle en ajoutant une légère perturbation sur un panneau de signalisation par exemple, alors la prise de décision du véhicule autonome pour mettre en danger les passagers ainsi que les individus à proximité.
(l’intégralité du code ayant servi à la rédaction de cet article est disponible ici : https://github.com/youness1301/FGSM_PGD_adversial_attacks)
1. FGSM (Fast Gradient Sign Method)
Le FGSM (Fast Gradient Sign Method) est une méthode d’attaque adversariale qui génère des exemples (images dans notre cas) perturbés en utilisant les gradients du modèle pour maximiser la fonction de perte du modèle et ainsi induire des erreurs de prédiction.
Prérequis nécessaires à l’attaque :
- posséder le modèle en local (whitebox)
a. Principe théorique
L’idée est de perturber l’entrée x en ajoutant un bruit ϵϵ (petite perturbation) dans la direction du gradient du modèle par rapport à la perte. Cela provoque une erreur dans la prédiction du modèle tout en créant une modification quasi invisible pour un être humain.
Mathématiquement la méthode FGSM se traduit de cette façon :
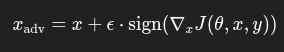
Avec :
- x_adv : l’entrée modifiée (résultat adversial)
- x : l’entrée d’origine
- epsilon : le facteur de perturbation
- J(teta,x,y) : la fonction de perte du modèle
- gradient_x : le gradient de la fonction de perte par rapport à l’entrée d’origine x
L’objectif de cette méthode est d’ajouter une perturbation à l’entrée d’origine imperceptible pour un humain, mais qui conduit le modèle à effectuer de mauvaises prédictions.
b. Démonstration
Reprenons l’exemple du modèle de vision capable de classifier les différentes espèces de chien:
pretrained_model = tf.keras.applications.MobileNetV2(include_top=True,
weights='imagenet')
pretrained_model.trainable = False
# ImageNet labels
decode_predictions = tf.keras.applications.mobilenet_v2.decode_predictions
Effectuons une prédiction avec cette image de boxer pour s’assurer que le modèle est fonctionnel :

def preprocess(image):
image = tf.cast(image, tf.float32)
image = tf.image.resize(image, (224, 224))
image = tf.keras.applications.mobilenet_v2.preprocess_input(image)
image = image[None, ...]
return image
#
def get_imagenet_label(probs):
return decode_predictions(probs, top=1)[0][0]
image_path = tf.keras.utils.get_file('boxer1.jpg', 'https://www.zooplus.fr/magazine/wp-content/uploads/2018/03/deutscher-boxer-tabby.jpg')
image_raw = tf.io.read_file(image_path)
image = tf.image.decode_image(image_raw)
image = preprocess(image)
image_probs = pretrained_model.predict(image)
plt.figure()
plt.imshow(image[0] * 0.5 + 0.5)
_, image_class, class_confidence = get_imagenet_label(image_probs)
plt.title('{} : {:.2f}% Confidence'.format(image_class, class_confidence*100))
plt.show()
ce qui nous donne :
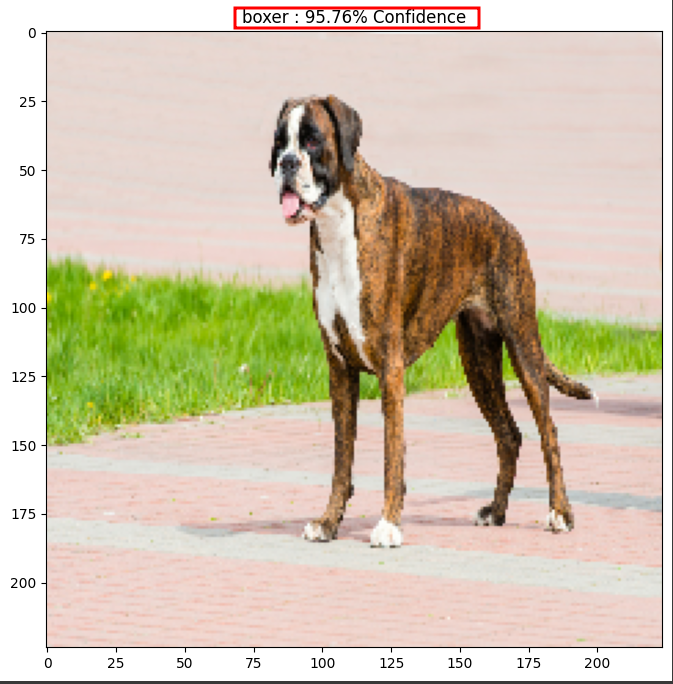
On remarque que le modèle a bien prédit la bonne espèce de chien.
Maintenant, déterminons les perturbations optimales pour dégrader les performances de détection du modèle tout en rendant les perturbations invisibles à l’œil humain :
loss_object = tf.keras.losses.CategoricalCrossentropy()
def create_adversarial_pattern(input_image, input_label):
with tf.GradientTape() as tape:
tape.watch(input_image)
prediction = pretrained_model(input_image)
loss = loss_object(input_label, prediction)
gradient = tape.gradient(loss, input_image)
signed_grad = tf.sign(gradient)
return signed_grad
boxer_index = 242
label = tf.one_hot(boxer_index, image_probs.shape[-1])
label = tf.reshape(label, (1, image_probs.shape[-1]))
perturbations = create_adversarial_pattern(image, label)
plt.imshow(perturbations[0] * 0.5 + 0.5);
Ce qui nous donne ce masque de perturbations :
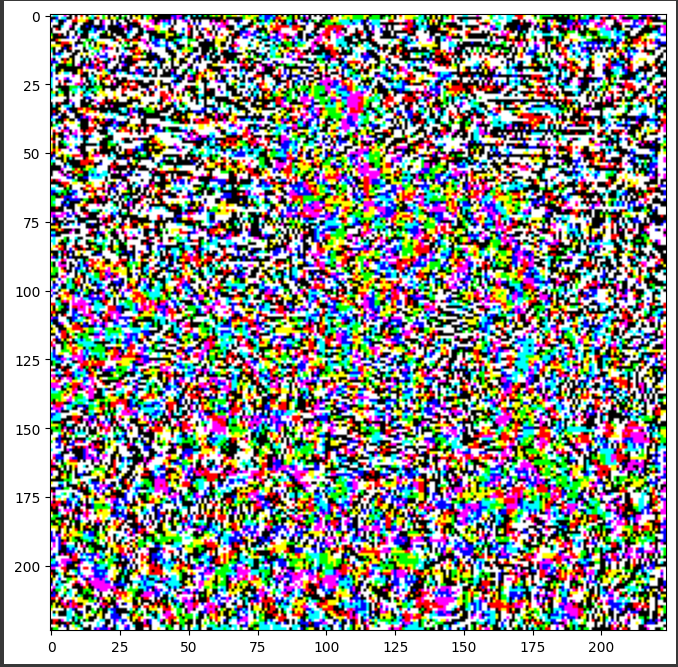
Maintenant que nous avons notre masque de perturbation optimal, nous pouvons l’appliquer à notre image d’origine avec plusieurs valeurs de coefficient de perturbation pour dégrader de plus en plus les performances du modèle :
def display_images(image, description):
_, label, confidence = get_imagenet_label(pretrained_model.predict(image))
plt.figure()
plt.imshow(image[0]*0.5+0.5)
plt.title('{} \n {} : {:.2f}% Confidence'.format(description,
label, confidence*100))
plt.show()
epsilons = [0.01]
descriptions = [('Epsilon = {:0.3f}'.format(eps) if eps else 'Input')
for eps in epsilons]
for i, eps in enumerate(epsilons):
adv_x = image + eps*perturbations
adv_x = tf.clip_by_value(adv_x, -1, 1)
display_images(adv_x, descriptions[i])
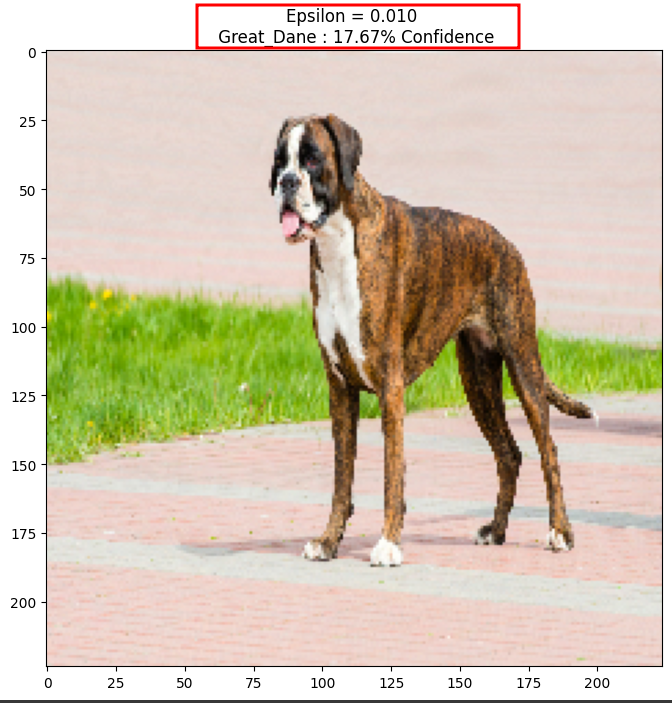
On observe qu’avec un coefficient de perturbation de 0.01 le modèle n’est plus en mesure de reconnaitre le boxer et reconnaît un dogue allemand à la place alors que les perturbations apportées à l’image d’origine sont presque imperceptibles par un être humain.
2. PGD (Projected Gradient Descent)
Le PGD (Projected Gradient Descent) est une attaque adversiale visant à dégrader les performances d’un modèle de machine learning. Le PGD se base sur la méthode du FGSM expliqué précédemment cependant, les perturbations apportées par ce type d’attaque sont réparties de manière optimale permettant une modification subtile, mais disposant d’un fort impact sur la qualité de prédiction du modèle.
Prérequis nécessaires à l’attaque :
- posséder le modèle en local (whitebox)
a. Principe théorique
De la même manière que la méthode FGSM décrite précédemment, l’idée de la méthode PGD est de modifier une entrée x en y ajoutant une perturbation. Cependant, le PGD, contrairement à la méthode FGSM, est une méthode itérative. En effet le PGD dégrade les performances du modèle en répétant plusieurs fois la méthode FGSM tout en projetant chaque masque de perturbation dans un intervalle restreint permettant une perturbation subtile sur l’intégralité de l’image rendant presque indétectables les modifications apportées sur l’image d’origine.
Pour chaque itération :
- on calcule le gradient de la fonction de perte par rapport à l’image actuelle
- on applique un coefficient de perturbation alpha (learning rate) (de la même manière que le FGSM)
- on projette l’image modifiée au sein d’un intervalle de perturbation toléré
La méthode PGD peut se traduire par la formule suivante :

Avec :
- x_t : image à l’étape t
- alpha : learning rate (coefficient de perturbation)
- Gradient (J(teta,x_t,y)) : gradient de la fonction de perte par rapport à l’entrée
- ΠBϵ : Projection de la perturbation au sein de l’intervalle de tolérance de perturbation
b. Démonstration
Implémentons la méthode PGD :
def pgd_attack(model, image, label, eps=0.03, alpha=0.005, iters=40):
# Initialiser avec l’image d’origine + petite perturbation aléatoire
adv_image = image + tf.random.uniform(shape=image.shape, minval=-eps, maxval=eps)
adv_image = tf.clip_by_value(adv_image, -1.0, 1.0)
for i in range(iters):
with tf.GradientTape() as tape:
tape.watch(adv_image)
prediction = model(adv_image)
loss = loss_object(label, prediction)
gradient = tape.gradient(loss, adv_image)
adv_image = adv_image + alpha * tf.sign(gradient)
# Projection : rester dans l'interval de perturbation autour de l’image originale
perturbation = tf.clip_by_value(adv_image - image, -eps, eps)
adv_image = tf.clip_by_value(image + perturbation, -1.0, 1.0)
return adv_image
eps = 0.01 # maximum perturbation
alpha = 0.01 # step size
iters = 30 # number of iterations
adv_image_pgd = pgd_attack(pretrained_model, image, label, eps=eps, alpha=alpha, iters=iters)
display_images(adv_image_pgd, f'PGD Attack\nEpsilon={eps}, Alpha={alpha}, Iters={iters}')
Ce qui nous donne :
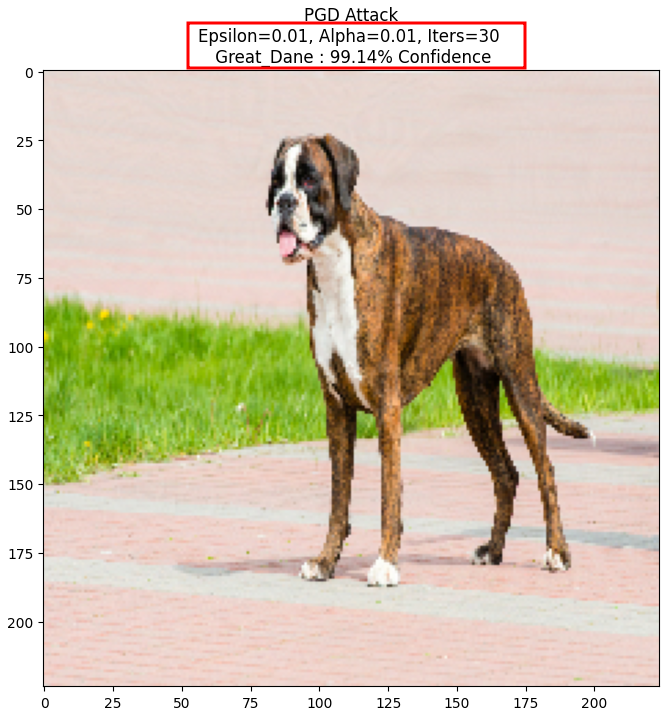
On observe que pour des valeurs similaires de perturbation, avec seulement 30 itérations, l’attaque via méthode PGD a dégradé suffisamment le modèle pour le rendre sûr à 99.14% que le boxer est en réalité un dogue allemand.

On observe qu’en comparaison avec le FGSM, la méthode PGD induit mieux en erreur le modèle puisque celui-ci prédit une espèce fausse de chien avec plus de confiance ainsi, la méthode PGD est plus efficace pour dégrader les performances de ce modèle.
III. Remédiation
Prémunir les modèles de vision de moyens de défense est un réel défi. Cependant il existe plusieurs mécanismes de protection qui peuvent pallier à ce genre d’attaque.
1. Adversial Training
L’une des méthodes les plus efficaces est l’adversial training. L’adversial training consiste à entrainer le modèle avec des images adversiales en plus des images classiques utilisées pour l’entrainement du modèle lui permettant de s’habituer à reconnaitre le bon label malgré des perturbations apportées aux images.
Ainsi, l’utilisation des méthodes FGSM et PGD appliquées aux images servant à l’entrainement du modèle permet au modèle de s’entrainer à reconnaitre les bons labels malgré des perturbations apportées aux images réduisant ainsi l’impact des attaques adversiales sur les performances du modèle.
L’avantage de l’adversial Training est que le modèle devient très robuste face aux attaques adversiales qu’il a déjà “vu” dans les données servant à l’entrainement du modèle. Cependant l’inconvénient d’une telle méthode est que le modèle ne devient robuste uniquement face aux attaques adversiales appliquées aux données d’entrainement. Ainsi, il est difficile de généraliser ce mécanisme de défense à l’intégralité des méthodes adversiales.
2. Input Preprocessing
Une autre méthode défensive contre les attaques adversiales sur des modèles de vision est la mise en place d’un mécanisme de nettoyage des images envoyées par l’utilisateur. Pour ce faire il est possible d’implémenter un DAE (Denoising autoencoders). Un DAE est modèle de machine learning permettant d’éliminer le bruit présent au sein d’une image permettant ainsi de réduire les perturbations causées par des attaques adversiales comme FGSM et PGD et donc de limiter l’impact de celles-ci sur les performances du modèle.
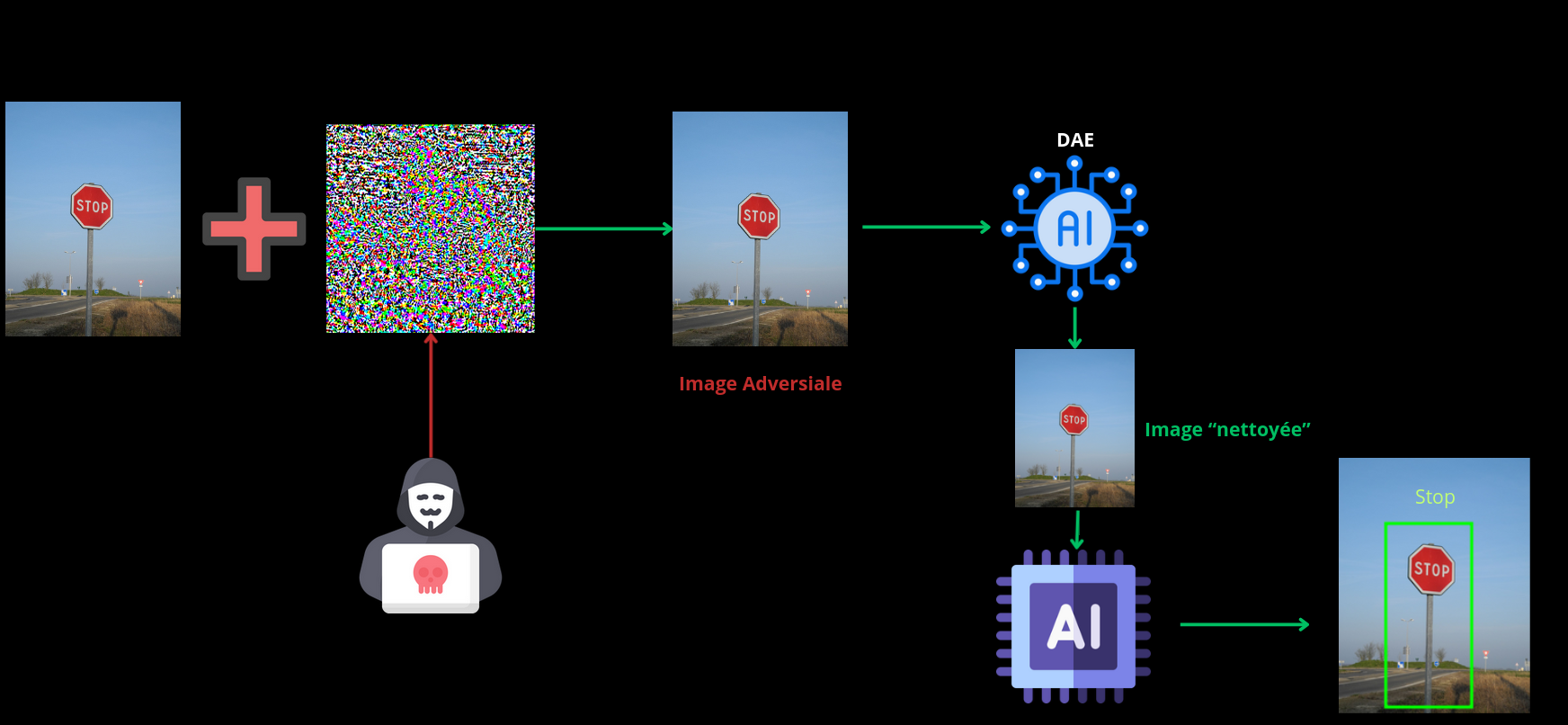
Cependant l’utilisation de modèles de Denoised Autoencoder peut réduire la qualité des images envoyées par le client et donc baisser la précision du modèle après la phase de nettoyage des images.
IV. Conclusion
Nous avons pu voir tout au long de cet article que les modèles de vision peuvent être amenés à être vulnérables à des attaques adverisales visant à dégrader les performances du modèle. Nous avons pu traiter du principe de fonctionnement ainsi que de l’implémentation de deux types d’attaque adversiales : le FGSM et le PGD. Enfin nous avons pu voir deux méthodes visant à limiter l’impact de ces différentes attaques.
Nous pouvons conclure que les attaques adversiales sur des modèles de vision peuvent avoir de terribles conséquences sur la sécurité en fonction du domaine d’application ainsi que le périmètre de déploiement du modèle. Cependant il existe des méthodes efficaces permettant une réduction de l’impact de ces attaques rendant l’utilisation des modèles de vision plus sûre.